We have been using machine learning algorithms (specifically lasso and ridge regression) to identify the genes that correlate with different clinical outcomes in cancer. Coming purely from a biology background, it is good to brush up on some statistics concepts to make sense of the results of these algorithms. This is a “note-to-self” type post to wrap my mind around how lasso and ridge regression works, and I hope it would be helpful for others like me. For more information, I recommend An Introduction to Statistical Learning, and The Elements of Statistical Learning books written by Garreth James, Daniela Witten, Trevor Hastie, and Robert Tibshirani (creators of few R packages commonly used for machine learning). The online course associated with the first book is available on EdX and it is taught by directly by Hastie and Tibshirani. Also, check out the StatQuest videos from Josh Starmer to get the intuition behind lasso and ridge regression.
For those who are new to these concepts, machine learning in a nutshell is using algorithms to reveal patterns in the data and to predict outcomes in some other datasets. Some of the numerous applications of ML include classifying disease subtypes (for instance, cancer), predicting purchasing behaviors of customers, and computer recognition of handwritten letters. Although there are several other machine learning algorithms, we will focus on lasso and ridge regression below.
Prepare toy data
To understand how these algorithms work, let’s make up a toy data frame about shark attacks. Imagine that we are trying to find out the factors that are associated with the number of shark attacks at a given location. Additionally, we might also want to make predictions about shark attacks based on other available data. In this example, the number of shark attacks is what’s called the response variable (the thing we are trying to study or predict). The other measurements in the data frame constitute the predictor variables (the thing that might/might not impact the response variable).
Our data frame will consist of 1000 daily measurements of the following independent variables:
attacks: Number of shark attacks (response variable)
swimmers: Number of swimmers in water
watched_jaws: Percentage of swimmers who watched iconic Jaws movies
temp: Average temperature of the day
stock_price: The price of your favorite tech stock that day (a totally unrelated variable)
Towards the end of the post, I will add co-linear (ie. correlated) variables and we will see how this impacts the results.
Code
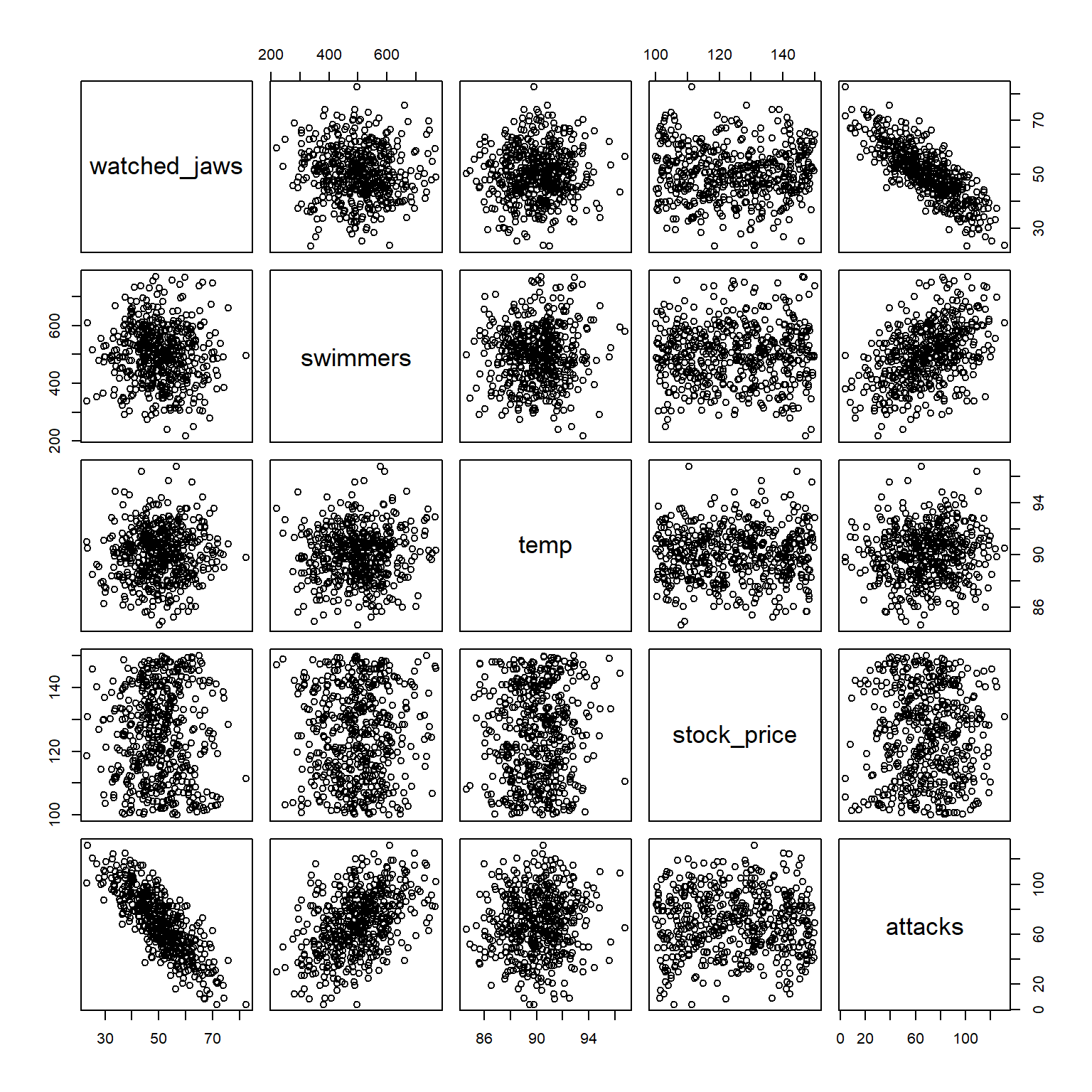
# For reproducible resultsset.seed(123)# Number of observationsnum <-500dat <-data.frame(watched_jaws =rnorm(n=num, mean=50, sd=10),swimmers =round(rnorm(n=num, mean=500, sd=100)),temp =rnorm(n=num, mean=90, sd=2),stock_price =runif(n=num, min =100, max=150))attacks <-round(rnorm(n=num, mean =30, sd=10)+# noise-2*dat$watched_jaws+# 1 fewer attack for 1 percent increase in Jaws movie audience0.1*dat$swimmers+# 1 more attack for each 10 swimmers on site1*dat$temp+# 1 more attack for each degrees of increase in temp0*dat$stock_price) # no relationshipdat$attacks <- attacksplot(dat)
Just eye-balling the data, we see some predictors are more strongly correlated with the number of shark attacks. For instance, the number of attacks decrease as the percent of people on the beach who watched Jaws movies increases. It makes sense, people may be more afraid of sharks if they watched the movies.
Quick intro
Lasso and Ridge regression are built on linear regression, and as such, they try to find the relationship between predictors (\(x_1, x_2, ... x_n\)) and a response variable (\(y\)). In general, linear regression tries to come up with an equation that looks like this:
Here, the coefficients \(\beta_1, \cdots ,\beta_n\) correspond to the amount of expected change in the response variable for a unit increase/decrease in the predictor variables. \(\beta_0\) is the intercept and it corresponds to the variation that is not captured by the other coefficients in the model (or alternatively the value of \(y\) when all the other predictors are zero).
In simple linear regression, the coefficients are calculated to minimize the difference between the observed value of the response variable (the actual value of \(y\)) and the predicted value of it (ie the value of \(y\) you get if you were to plug in \(\beta\)’s and \(x\)’es in the equation). This difference is termed as “residuals”, and the linear regression calculates coefficients that minimize sum of all squared residuals (ie. residual sum of squares, RSS). This is because the best fitting line should have the least RSS:
Lasso and Ridge regression applies a mathematical penalty, lambda (\(\lambda \geq 0\)), on the predictor variables and tries to minimize the following:
For the curious, Ridge’s penalty term (marked in red above) is called \(\ell_2\) norm (pronounced ell 2, written mathematically as \(\left\lVert\beta\right\lVert_2\)), and Lasso’s penalty term (marked in blue) is called \(\ell_1\) (pronouced ell 1, writen mathematically as \(\left\lVert\beta\right\lVert_1\)).
When we are trying to minimize these equations, there are two competing sides:
While calculating the \(RSS\) part, some \(\beta\) coefficients may need to be large to keep \(RSS\) small.
However, large \(\beta\) values would also mean that penalty term will be higher, working against the goal of minimizing the total sum. In other words, there is a constraint, or “budget”, for how high the coefficients get.
Thus, as \(\lambda\) increases, \(\beta\) coefficients decrease to minimize the whole equation. This is known as “shrinkage”, and it allows us to focus on the strongest predictors in the dataset.
Simple linear modeling
Let’s take a look at how simple linear modeling looks on this data set:
Code
# Regress all the predictor variables onto "attacks" response variableres <-lm(attacks~., data=dat)summary(res)
Call:
lm(formula = attacks ~ ., data = dat)
Residuals:
Min 1Q Median 3Q Max
-26.8792 -6.4153 -0.0898 6.3496 28.3437
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 17.589441 20.056159 0.877 0.381
watched_jaws -2.009191 0.044882 -44.767 < 2e-16 ***
swimmers 0.099463 0.004317 23.040 < 2e-16 ***
temp 1.158478 0.219964 5.267 2.08e-07 ***
stock_price -0.010302 0.030292 -0.340 0.734
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 9.721 on 495 degrees of freedom
Multiple R-squared: 0.8437, Adjusted R-squared: 0.8424
F-statistic: 667.8 on 4 and 495 DF, p-value: < 2.2e-16
Since we made up the data by adding predictors independently, all except stock_price were significantly associated with the number of attacks (note the low p-values under Pr(>|t|) column, or asterisks). Estimate column indicates the predicted coefficients for each variable, which are in agreement with our hard-coding during data prep.
Ridge regression
Let’s see how the coefficients will change with Ridge regression. Ridge regression imposes a penalty on the coefficients to shrink them towards zero, but it doesn’t set any coefficients to zero. Thus, it doesn’t automatically do feature selection for us (i.e. all the variables we feed in the algorithm are retained in the final linear formula, see below).
Code
library(glmnet)
Loading required package: Matrix
Loaded glmnet 4.1-10
Code
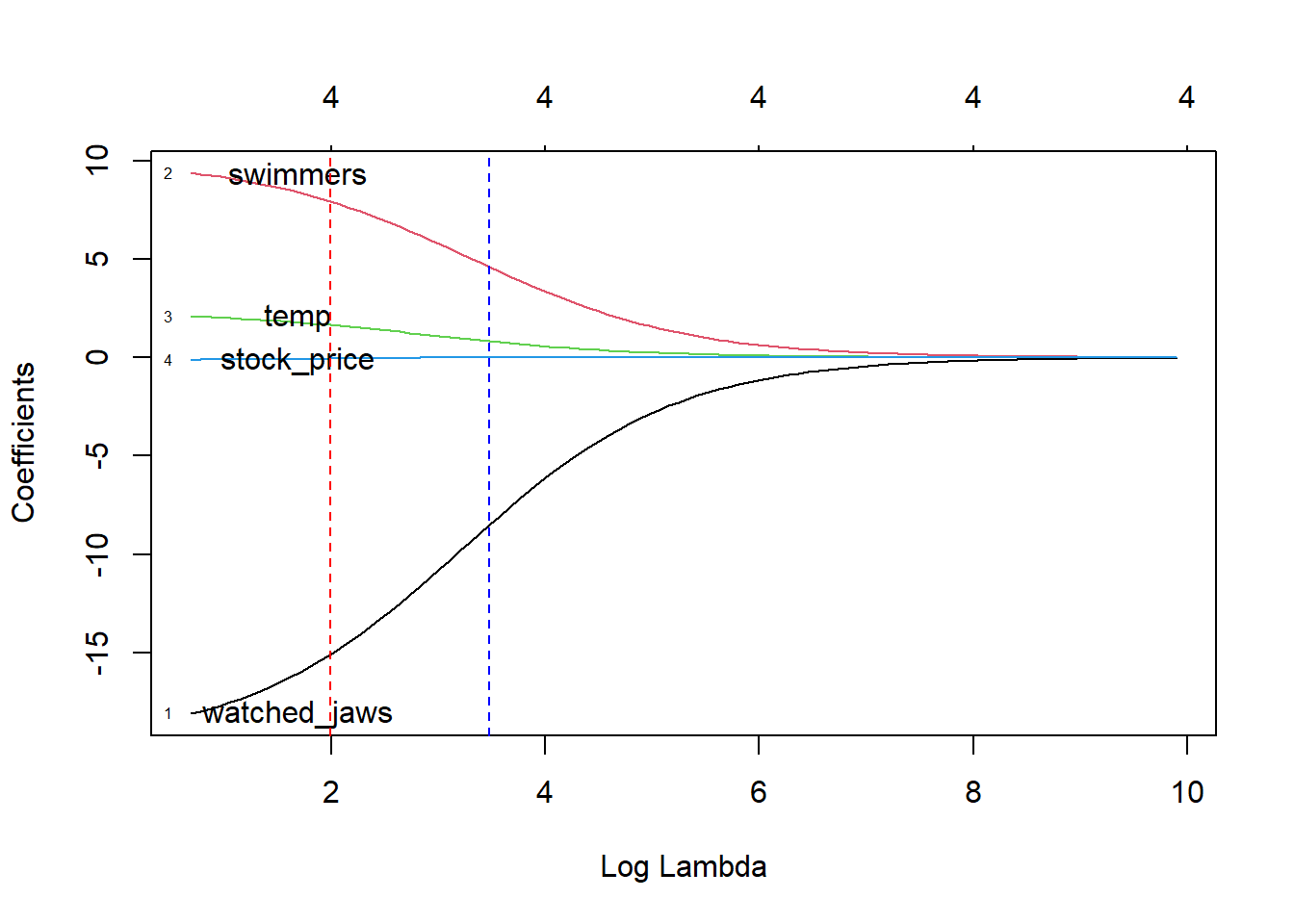
# Prepare glmnet input as matrix of predictors and response var as vectorvarmtx <-model.matrix(attacks~.-1, data=dat)response <- dat$attacks# alpha=0 means ridge regression. ridge <-glmnet(scale(varmtx), response, alpha=0)# Cross validation to find the optimal lambda penalizationcv.ridge <-cv.glmnet(varmtx, response, alpha=0)# Create a function for labeling the plot belowlbs_fun <-function(fit, offset_x=1, ...) { L <-length(fit$lambda) x <-log(fit$lambda[L])+ offset_x y <- fit$beta[, L] labs <-names(y)text(x, y, labels=labs, ...)}plot(ridge, xvar ="lambda", label=T)lbs_fun(ridge)abline(v=cv.ridge$lambda.min, col ="red", lty=2)abline(v=cv.ridge$lambda.1se, col="blue", lty=2)
This plot shows us a few important things:
Y-axis: Regularized coefficients for each variable (ie. coefficients after penalization is applied)
X-axis: Logarithm of the penalization parameter Lambda (\(\lambda\)). The higher value of lambda indicates more regularization (ie. reduction of the coefficient magnitude, or shrinkage)
Curves: Change in the predictor coefficients as the penalty term increases.
Numbers on top: The number of variables in the regression model. Since Ridge regression doesn’t do feature selection, all the predictors are retained in the final model.
Red dotted line: The minimum value of lambda (lambda.min) that results in the smallest cross-validation error. This is calculated by dividing the dataset in ten subsets, followed by the calculation of fit in 9/10 of the subsets and testing the predicted model on the remaining 1/10. We would use ideally use this lambda value (or lambda.1se below) as our penalization level for predicting outcomes in a new dataset.
Blue dotted line: The largest value of lambda (ie. more regularized) within the 1 standard error of the lambda.min. This lambda.1se value corresponds to a higher level of penalization (ie more regularized model) and can be chosen for a simpler model in predictions (less impact from from coefficients)
Log Lambda = 0 corresponds to “no regularization” (ie. regular linear model with minimum residual sum of squares).
The way we read the plot is as follows:
Among the variables in the data frame, watched_jaws has the strongest potential to explain the variation in the response variable, and this remains true as the model regularization increases. swimmers has the second strongest potential to model the response, but it’s importance diminishes near zero as the regularization increases.
Lasso regression
Now, let’s take a look at the lasso regression. This method uses a different penalization approach which allows some coefficients to be exactly zero. Thus, lasso performs feature selection and returns a final model with lower number of parameters.
Code
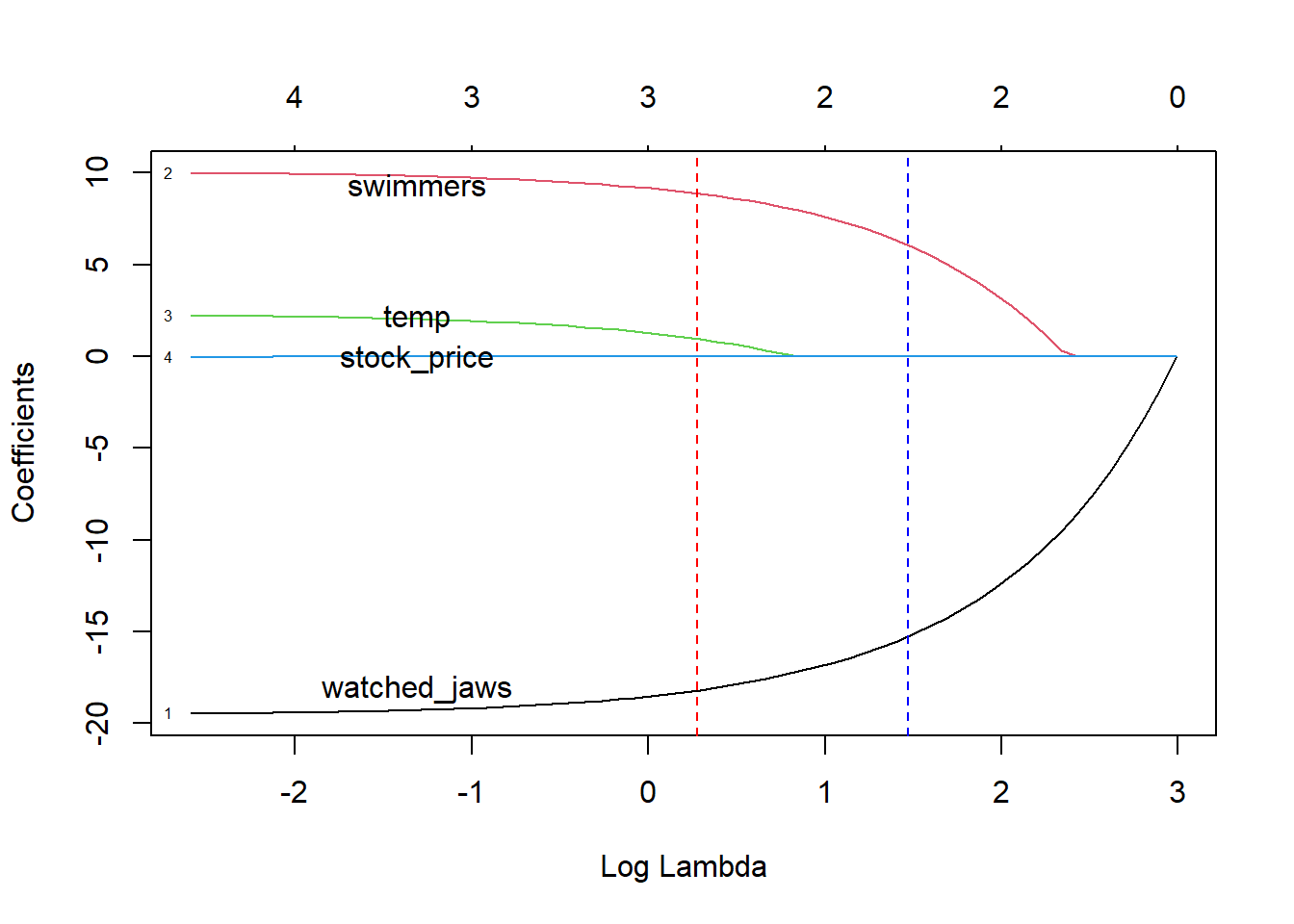
# alpha=1 means lasso regression. lasso <-glmnet(scale(varmtx), response, alpha=1)# Cross validation to find the optimal lambda penalizationcv.lasso <-cv.glmnet(varmtx, response, alpha=1)plot(lasso, xvar ="lambda", label=T)lbs_fun(ridge, offset_x =-2)abline(v=cv.lasso$lambda.min, col ="red", lty=2)abline(v=cv.lasso$lambda.1se, col="blue", lty=2)
The main difference we see here is the curves collapsing to zero as the lambda increases. Dashed lines indicate the lambda.min and lambda.1se values from cross-validation as before. watched_jaws variable shows up here as well to explain shark attacks. If we choose the lambda.min value for predictions, the algorithm would utilize data from both swimmers, watched_jaws, and temp variables. If we choose lambda.1se instead (blue dashed line), we would predict only using the watched_jaws and swimmers variables. This means at this level of penalization, temp isn’t as important for modeling shark attacks. stock_price has zero coefficient (no impact on the response) as in ridge regression. Pretty neat, especially if you are trying to find a needle (important predictor) in the haystack (whole bunch of other unimportant predictors). For me, the needles were genes associated with clinical outcome in cancer patients, and the haystack was the entire human genome!
Problem of co-linearity
Strong correlation between predictors, or co-linearity, is a problem in machine learning since it can make predictions unstable. The essence of the issue is the following. Consider two predictor variables, \(x_1\) and \(x_2\), which are perfectly correlated with each other. In this case, the fitted regression formula can be written in many equivalent ways (arrows indicate changing coefficients where the change in one can be balanced by the changes in the other):
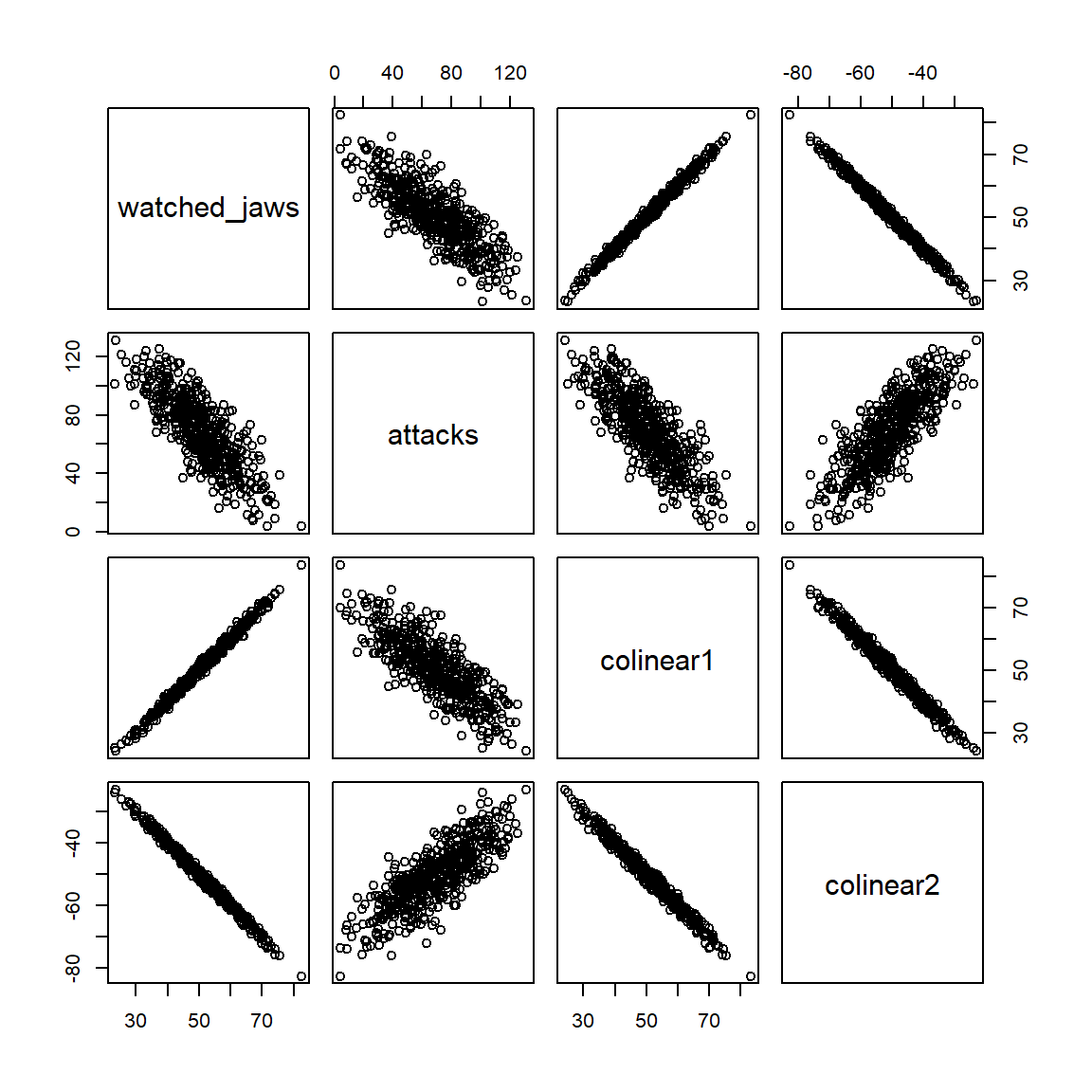
Let’s see how ridge and lasso behaves when we added strong co-linear predictors. I’m going to add two variables, colinear1 and colinear2 , that closely follow watched_jaws variable.
# Prepare glmnet input as matrix of predictors and response var as vectorvarmtx <-model.matrix(attacks~.-1, data=dat)response <- dat$attacks# alpha=0 means ridge regression. ridge2 <-glmnet(scale(varmtx), response, alpha=0)# Cross validation to find the optimal lambda penalizationcv.ridge2 <-cv.glmnet(varmtx, response, alpha=0)# alpha=1 means lasso regression. lasso2 <-glmnet(scale(varmtx), response, alpha=1)# Cross validation to find the optimal lambda penalizationcv.lasso2 <-cv.glmnet(varmtx, response, alpha=1)
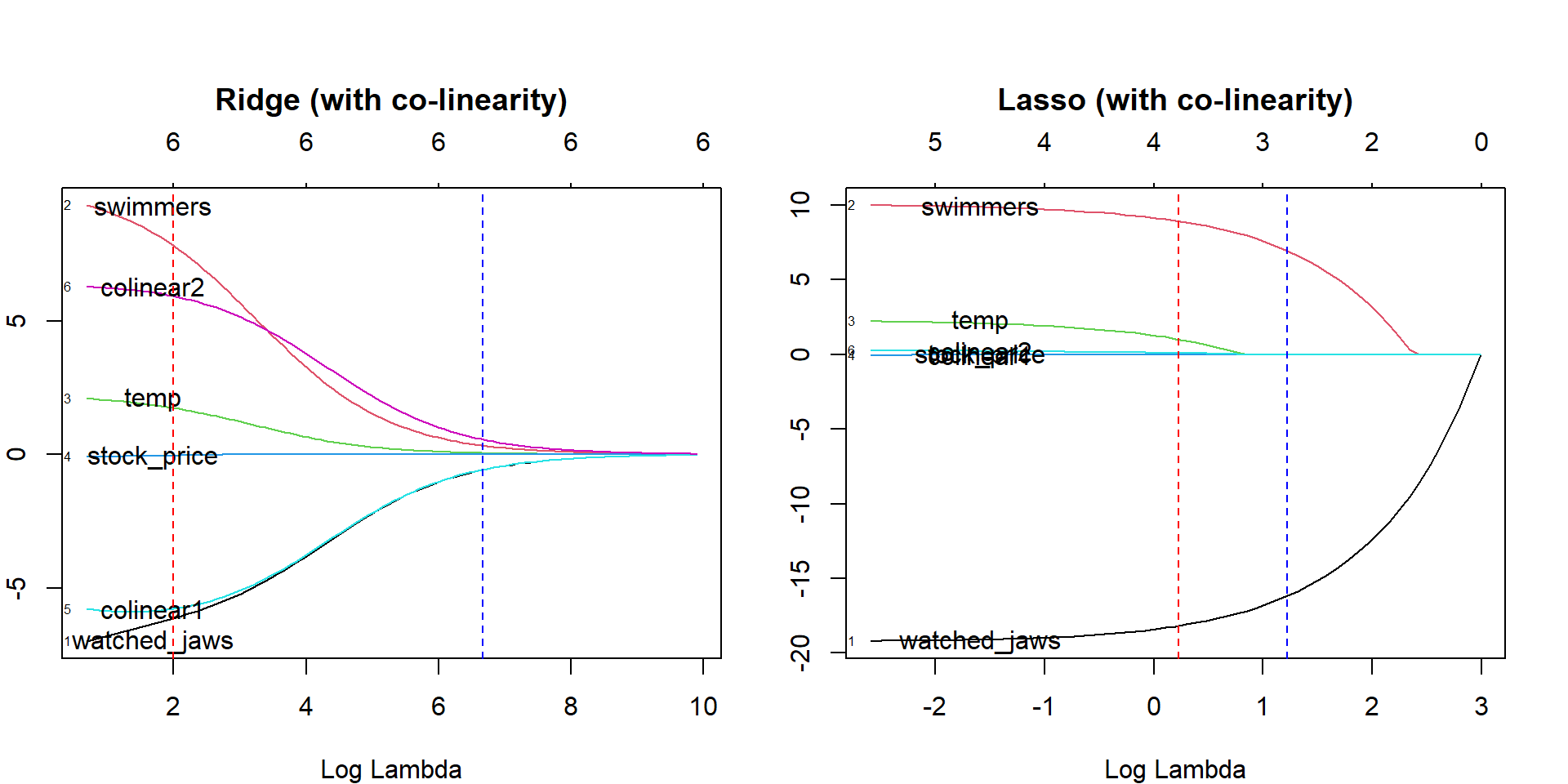
As we can see here, lasso and ridge performs quite differently when there are correlated variables. Ridge treats the correlated variables in the same way, (ie. it shrinks their coefficients similarly), while lasso collapses some of the correlated parameters to zero (note colinear1 and colinear2 are zero along the regularization path). In other words, lasso drops the co-linear predictors from the fit. This is an important point to consider when analyzing real world data. One can think of looking at correlation matrices to examine the variables before the analysis. Alternatively we can perform both lasso and ridge regression and try to see which variables are kept by ridge while being dropped by lasso due to co-linearity. We didn’t discuss in this post, but there is a middle ground between lasso and ridge as well, which is called the elastic net. Using this method is very simple, and it requires setting alpha parameter between 0 and 1. In a future follow-up post, we will examine at which point co-linearity becomes an issue and how it will impact prediction performance. Until then, I will leave you with a couple of take home points:
Linear modeling, lasso, and ridge try to explain the relationship between response and predictor variables
Both lasso and ridge impose a penalty term (lambda) on the coefficients of predictors (althought the math is different)
Lasso can shrink coefficients all the way to zero resulting in feature selection
Ridge can shrink coefficients close to zero, but it will not set any of them to zero (ie. no feature selection)
Co-linearity can be a problem in both methods, and they produce different results for correlated variables